MSD: Mixing Signed Digit Representations for Hardware-efficient DNN Acceleration on FPGA with Heterogeneous Resources
Abstract
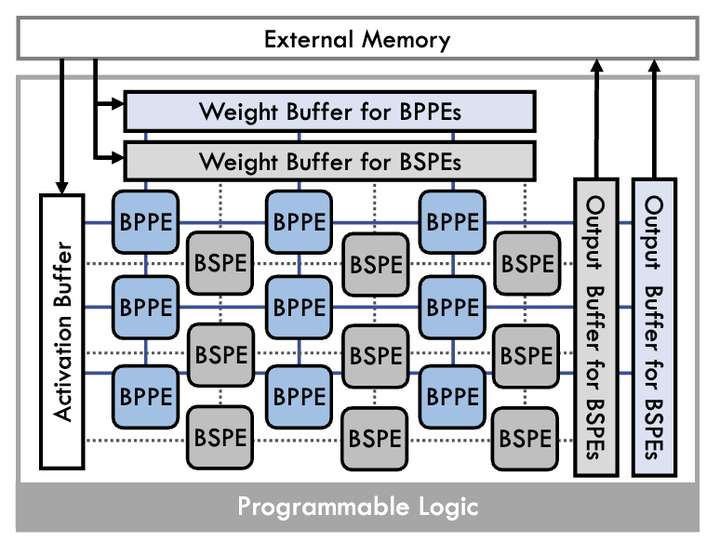
While quantizing deep neural networks (DNNs) to 8-bit fixed point representations has become the de facto technique in modern inference accelerator designs, the quest to further improve hardware efficiency by reducing the bitwidth remains a major challenge due to (i) the significant loss in accuracy and (ii) the need for specialized hardware to operate on these ultra-low bitwidth data that are not readily available in commodity devices. By employing a mix of a novel restricted signed digit (RSD) representation that utilizes limited number of effectual bits and the conventional 2’s complement representation of weights, a hybrid approach that employs both the fine-grained configurable logic resources and coarse-grained signal processing blocks in modern FPGAs is presented. Depending on the availability of fine-grained and coarse-grained resources, the proposed framework encodes a subset of weights with RSD to allow highly efficient bit-serial multiply-accumulate implementation using LUT resources. Furthermore, the number of effectual bits used in RSD is optimized to match the bit-serial hardware latency to the bit-parallel operation on the coarse-grained resources to ensure the highest run time utilization of all on-chip resources. Experiments show that the proposed mixed signed digit (MSD) framework can achieve a 1.52$\times$ speedup on the ResNet-18 model over the state-of-the-art, and a remarkable 4.78% higher accuracy on MobileNet-V2.
The final version of pdf file and the conference poster/video will be uploaded in the future. Doi is not the real one now.
Jiajun Wu
Post-doc Fellow
My research interests include Hardware acceleration system, reconfigurable computing and AI chip compiler.